Muatan :
- Kilasan tentang unique data dan sort data
- Contoh penyusunan unique data yang terurutkan
- Langkah-langkah kalkulasi pada salah satu cell hasil
Kilasan
Penyusunan laporan yang berisi nilai agregat umumnya memiliki
kolom-kolom (minimal 1 kolom) yang menjadi dasar penyusunan agregat
tersebut. Kolom-kolom ini menjadikan baris-baris data laporan bersifat
unik.Pada laporan jenis tertentu membutuhkan pengurutan berdasar prioritas tertentu, seperti laporan keterlambatan proses. Laporan ini membutuhkan pengurutan berdasar total waktu keterlambatan dari masing-masing proses. Total waktu keterlambatan menjadi prioritas penyusunan laporan yang terurut dari paling terlambat hingga mendekati terlambat.
Contoh lainnya adalah laporan pencapaian penjualan per produk yang berasal dari data sumber yang tersusun berdasar kegiatan transaksi penjualan (invoice). Laporan akan disusun berdasar produk yang volume penjualannya terurut dari volume tertinggi sampai volume terendah. Hasil laporan akan berupa data unik per produk mulai dari volume penjualan tertinggi sampai terendah.
Penyusunan keunikan hasil laporan membutuhkan kriteria yang menyertakan jumlah total volume penjualan sebagai prioritas pertama (kriteria pertama). Kriteria ini sering disebut sebagai composite key.
Penyusunan data unik terurut
Data pada gambar berikut (kolom A) adalah contoh composite key
yang akan menjadi dasar penyusunan data hasil (laporan). Laporan
bersifat unik dengan prioritas pengurutan hasil berdasar suatu urutan
tertentu yang menjadi struktur dari composite key.

Duplikasi data tampak pada kolom A, yang kemudian diolah menjadi keluaran bersifat unik dan terurut. Hasil pengolahan akan menghasilkan error value #N/A (baris 10 Excel) yang menandakan bahwa seluruh data telah diolah dan tidak ada yang dapat ditampilkan sebagai data keluaran. Hal ini memberi tanda batas baris yang harus berisi formula, sehingga proses Copy formula menjadi lebih mudah untuk disesuaikan dengan kebutuhan.
Cell yang diberi warna latar biru adalah cell yang akan dibahas lebih detil setiap proses kalkulasi array formula yang digunakan untuk penyusunan data unik terurut ini. Cell tersebut adalah cell C4 yang merupakan item ke-3 dari data hasil. Array formula yang digunakan pada cell ini adalah :
=INDEX($A$2:$A$18,
MATCH( SUM( COUNTIF($A$2:$A$18,C$1:C3) ),
COUNTIF($A$2:$A$18,"<" & $A$2:$A$18), 0 ) )
Garis besar proses pengolahan data unik terurut
Pokok pertama yang diperhatikan adalah proses pengurutan. Pengurutan
data selalu berdasar proses perbandingan antar item data, dalam hal ini
adalah data sumber. Secara sederhana, berdasar jumlah cacah seluruh item data sumber yang kurang dari item tertentu dari data sumber dapat menjadi dasar pengurutan.Pada data yang bersifat unik, maka penjumlahan jumlah cacah seluruh item hasil (yang telah diperoleh di data hasil) dalam data sumber, menghasilkan nilai yang sama dengan jumlah cacah seluruh item data sumber dalam data sumber yang kurang dari item tertentu dari data sumber.
Item hasil yang baru adalah item pada data sumber yang memiliki jumlah cacah seluruh item data yang kurang dari item tertentu dari data sumber yang sama nilainya dengan penjumlahan jumlah cacah seluruh item hasil (yang telah diperoleh di data hasil) dalam data sumber. Fungsi COUNTIF dapat digunakan untuk 2 (dua) hal, yaitu :
- Menyusun array jumlah cacah masing-masing item data sumber dalam data sumber. Susunan fungsi CountIF berupa :
- COUNTIF(data_sumber, "<" &data_sumber)
- Menyusun array jumlah cacah masing-masing item hasil (yang telah
diperoleh di data hasil) dalam data sumber. Susunan fungsi CountIF
berupa :
- COUNTIF(data_sumber,data_hasil_yang_ada)
- SUM(COUNTIF( data_sumber , data_hasil_yang_ada ))
Langkah-langkah kalkulasi pada cell C4
Array formula untuk cell C4 (data hasil ke-3) adalah=INDEX($A$2:$A$18,
MATCH( SUM( COUNTIF($A$2:$A$18,C$1:C3) ),
COUNTIF($A$2:$A$18,"<" & $A$2:$A$18), 0 ) )
Proses kalkulasi array formula ini melalui 3 tahap utama, yaitu :
- Penyusunan lookup_value (Step1 dan Step2)
Tahap ini mengkalkulasi bagian :
SUM( COUNTIF( $A$2:$A$18 , C$1:C3 ) )
seperti gambar dibawah ini.Step1 menghasilkan sebuah array sejumlah hasil yang telah diperoleh ditambah 1 baris header. Pada item hasil ke-3 untuk cell C4 ini, telah dimiliki 2 item hasil, maka array terdiri dari 3 item.
Step2 adalah proses menjumlahkan seluruh item array hasil Step1. Hasilnya adalah sebuah nilai. Nilai hasil Step2 ini adalah lookup_value yang akan digunakan pada tahap berikutnya. - Penyusunan lookup_array (Step3)
Tahap ini mengkalkulasi bagian :
COUNTIF( $A$2:$A$18 , "<" & $A$2:$A$18 ) dan hasilnya berupa array sebanyak item data sumber, dengan nilai berupa jumlah masing-masing item pada data sumber yang kurang dari (<) item masing-masing, seperti gambar dibawah ini.Jika data sumber tidak bersifat unik, maka akan ditemui bahwa untuk item yang sama memiliki nilai jumlah yang sama. Misal seperti item array hasil ke-1 dan ke-9 memiliki nilai 4. Item ke-1 adalah data sumber yang nilainya 'C'.
- Mencari nomor index data yang akan menjadi item hasil dan mengambil nilai datanya (Step4 dan Step5)
Tahap ini adalah proses pengambilan data menggunakan fungsi INDEX dan MATCH. Gambar berikut ini adalah detil dari proses tahap ini.Step4 adalah proses lookup mencari nomor index data lookup_array hasil Step3 yang urutannya adalah sesuai data sumber, berdasar lookup_value hasil Step2, dengan tipe pencarian yang exact (match_type = 0).
Step5 adalah proses pengambilan nilai data sumber sesuai nomor index data hasil Step4.



Closing :
Step4 bisa dipisah dengan Step5 dalam 2 kolom, yaitu Step4 sebagai kolom
bantu berisi nomor index data sumber yang akan menjadi item hasil
berikutnya. Step5 sebagai kolom bantu berisi composite key yang
digunakan oleh Step4. Dengan begitu, maka untuk menampilkan kolom-kolom
lain dapat langsung merujuk pada hasil Step4 yang telah terpisah dari
hasil Step5.Secara tidak langsung, Step4 membutuhkan hasil Step5 hasil proses untuk item hasil sebelumnya, karena Step4 menggunakan hasil Step1, yang membutuhkan secara langsung hasil Step5 item hasil sebelumnya. Jadi hasil Step5 saat ini, akan digunakan oleh Step1 proses kalkulasi item hasil berikutnya (cell C5).
Perbedaan antara pengurutan menaik (Asc) dengan menurun (Desc) adalah pada penggunaan karakter yang berfungsi sebagai pembanding pada Step3, yaitu :
- karakter '<' untuk pengurutan menaik
- karakter '>' untuk pengurutan menurun
File(s) :
Coretan terkait :
- Array Formulas. Kenalan yuuk !
- LookUp ke kiri atau ke kanan untuk satu kriteria
- Formula penyusun data unique dan penghitung jumlah cacah data unique
- Formula sort data pada data teks
Selasa, 29 Maret 2011
Formula penyusun data unique dan penghitung jumlah cacah data unique
Muatan :
- Kilasan tentang data unique
- Memahami langkah penyusunan data unique
- Beberapa fungsi yang dapat digunakan dalam penyusunan data unique
- Contoh penerapannya pada sebuah kasus
Kilasan
Data unik (unique) adalah data yang tidak mengalami duplikasi berdasar
suatu kriteria, seperti nama-nama produk pada sebuah tabel referensi.
Data unik tidak selalu hanya pada tabel referensi. Banyak laporan yang
menyuguhkan nilai agregat. Tentu saja sifat data laporan ini adalah
unik. Ada laporan yang berupa summary yang berisi seluruh item tabel
referensi yang telah bersifat unik. Ada pula yang berupa summary data
penggalan data dalam kurun waktu tertentu.Umumnya data yang memiliki dimensi waktu sangat besar kemungkinannya tidak bersifat unik disuatu kolom, meskipun sebagai sebuah record adalah unik. Misalnya, seorang nasabah sebuah bank menerima kiriman penghasilan dari tempatnya bekerja secara rutin sebulan sekali. Data ini dicatat oleh pihak bank. Data bank tentang nasabah ini pada kurun waktu triwulan terakhir akan berisi 3 baris data penerimaan. Laporan penerimaan tentang total penerimaan nasabah tersebut adalah 1 baris. Jadi ada sebuah proses penyusunan data berdasar nama nasabah yang bersifat unik dari sebuah sumber data yang tidak unik. Besar kemungkinan untuk terjadi, dalam suatu rentang waktu, tidak seluruh nasabah memiliki jumlah baris data sumber yang sama.
Beberapa fungsi yang dapat digunakan
Garis besar proses penyusunan data unik adalah mengelompokkan data sumber yang belum masuk ke dalam data hasil berdasar suatu kriteria. Frase yang digaris bawahi memberi gambaran bahwa terjadi proses pemeriksaan antara data hasil dengan data sumber. Jika sebuah data sumber belum ada
di dalam data hasil, maka sebuah data sumber tersebut akan diambil
untuk dimasukkan ke dalam data hasil. Proses pemeriksaan ini dapat
dilakukan dengan menggunakan fungsi CountIF untuk mengkalkulasi jumlah baris hasil yang sama dengan setiap item kriteria keunikan di dalam data sumber.Setelah diketahui jumlah masing-masing item kriteria data sumber di dalam data hasil, maka perlu didapatkan sebuah item data sumber yang ditemukan pertama kali, yang belum terdapat pada data hasil. Fungsi Match dan fungsi Index dapat digunakan. Fungsi Match adalah penentu posisi baris data sumber yang akan diambil sebagai sebuah item yang menambah jumlah data hasil. Fungsi Index dengan dibantu hasil fungsi Match bertugas sebagai pengambil data.
Proses untuk mendapatkan sebuah item pada data hasil selalu melalui kalkulasi terhadap seluruh item data sumber dan data hasil. Array formula dibutuhkan untuk proses penyusunan data hasil.
Penerapan
Gambar berikut ini adalah data nomor rekening nasabah (kolom A) dan contoh penerapannya.

- Permintaan jumlah nomor rekening yang melakukan kegiatan transaksi perbankan minggu ini
- array formula :
=SUM((LEN(A$2:A$18)>0)/COUNTIF(A$2:A$18,A$2:A$18)) - formula : (bukan array formula)
=SUMPRODUCT((LEN(A$2:A$18)>0)/COUNTIF(A$2:A$18,A$2:A$18))
Setiap rekening bisa melakukan banyak transaksi. Kasus seperti ini muncul ketika tidak dibutuhkan detil data summary uniknya. Andai diminta bersama data summary uniknya, maka masalah ini dapat diselesaikan dengan formula
=COUNTIF(E3:E11,"<>#N/A")
Masalah ini tidak mengharapkan atau tidak tersedia data summary unik. Penyelesaian dilakukan menggunakan array formula yang prinsipnya adalah 1/n * n = 1. Array formula tersebut adalah :
=SUM(1/COUNTIF(A$2:A$18,A$2:A$18))
Step 1 :
- mengetahui jumlah record kolom kriteria pada data sumber yang
memiliki kriteria yang sama dengan setiap record dari kolom kriteria
pada data sumber.
- mengkalkulasi nilai satu per masing-masing hasil step 1.
- menjumlahkan seluruh hasil step 2.

=SUMPRODUCT(1/COUNTIF(A$2:A$18,A$2:A$18))
Jika ada data blank dan akan diabaikan, maka nilai 1 pada 1/n diganti dengan proses perbandingan panjang teks setiap item data sumber lebih dari 0. Formula akan berubah menjadi
Masalah 2 :
- Menyusun daftar nomor rekening yang melakukan kegiatan transaksi minggu ini
Array formula untuk masalah ini adalah :
=INDEX(A$2:A$18, MATCH(, COUNTIF(E$2:E2,A$2:A$18) ,0) )
Copy formula ke baris data hasil berikutnya. Hasil berupa error value #N/A menjadi tanda bahwa seluruh data sumber telah diperiksa dan dikeluarkan hasil yang sesuai kriteria.
Proses kalkulasi di dalam setiap cell hasil adalah :
Step 1 : COUNTIF(E$2:E2,A$2:A$18)
- kalkulasi jumlah setiap item data sumber (setiap cell pada A$2:A$18)
pada data hasil (range E$2:E2). Hasilnya adalah sebuah array dengan
jumlah element sebanyak jumlah data di data sumber (A$2:A$18). Nilai
hasil adalah 0 (belum ada di data hasil) atau 1 (sudah ada di data hasil
sebanyak 1 item).
- mencari posisi nilai 0 (belum ada di data hasil) yang pertama kali
ditemukan, pada array hasil step 1, dengan tipe pencarian 0 (exact
match). Hasilnya adalah posisi data pada data sumber yang pantas menjadi
data hasil berikutnya.
- mengambil data hasil berikutnya dari data sumber pada posisi baris ke-hasil step 2.

File(s) :
Coretan terkait :
- Array formula
- LookUp ke kiri atau ke kanan untuk satu kriteria
- Menghilangkan Duplikasi Data. Mungkinkah Case Sensitive ?
Senin, 07 Februari 2011
Menghilangkan Duplikasi Data. Mungkinkah Case Sensitive ?
Muatan :
- Kilasan tentang duplikasi dan fitur Excel
- Fitur Advanced Filter
- Fitur Remove Duplicates
- Dampak spasi berlebih di sebelum, di sesudah, atau di dalam teks
- Menghilangkan duplikasi data dengan mempertimbangkan case sensitive
Kilasan
Umumnya suatu data tidak dikehendaki adanya duplikasi record yang tidak
sesuai dengan kenyataan. Contohnya adalah data nasabah. Tidak tepat jika
terdapat lebih dari satu record yang dimiliki seorang nasabah dengan
seluruh nilai kolomnya sama. Sedangkan untuk transaksi yang dilakukan
nasabah dengan mengabaikan waktu transaksi, sangat mungkin terjadi lebih
dari satu transaksi dengan nilai transaksi yang sama. Untuk jenis
seperti data transaksi tersebut, duplikasi dihilangkan disertai dengan
penjumlahan nilai transaksi. Data transaksi seperti ini bisa saja
disimpan apa adanya. Pada data referensi seperti data nasabah, proses
entry data memungkinkan terjadinya duplikasi, tetapi penyimpanan data
tetaplah dituntut untuk unique records.Excel memiliki fitur yang dapat dimanfaatkan untuk menghilangkan duplikasi data. Fitur tersebut adalah Advanced Filter (pada seluruh versi Excel) dan Remove Duplicates (mulai Excel 2007). Kedua fitur ini bekerja dengan tidak mempedulikan huruf kapital atau bukan, yang sering disebut case insensitive. Record yang diambil adalah yang pertama kali ditemukan. Data Tabel berikut adalah contoh data yang akan digunakan pada kasus ini. (terimakasih kepada Pak Fauzi yang telah menyediakan data ini)

warna hijau muda menunjukkan adanya spasi di sebelum atau sesudah teks
Fitur Advanced Filter
Salah satu kemampuan fitur ini adalah menampilkan atau mengekstrak unique records dari suatu data. Cara mengaktifkan fitur ini :
- Excel 2003 ke bawah
Data -> Filter -> Advanced Filter - Excel 2007 ke atas
Data -> bagian Sort & Filter -> Advanced

- Action
Bagian ini memiliki 2 (dua) pilihan, yaitu : - Filter the list, in-place
Akan menghasilkan list terfilter (perhatikan nomor baris)
- Copy to another location
Opsi ini membutuhkan input lokasi hasil filter yang harus diisi pada bagian Copy to. Hasil akan berupa hasil ekstraksi data ke lokasi yang ditentukan tersebut.
- List range
Adalah data yang akan di-Advanced Filter - Criteria range
Adalah range yang berisi kriteria filter (untuk kasus ini, bagian kriteria tidak perlu diisi) - Copy to
Adalah range lokasi hasil ekstraksi yang harus diisi jika bagian Action dipilih Copy to another location. - Unique records only
Berupa checkbox yang harus dicentang jika ingin menghasilkan unique records dari data pada bagian List range.


Fitur Remove Duplicates (Excel 2007 ke atas)
Fitur ini secara muncul mulai Excel 2007. Ditujukan untuk memberi
keleluasaan pemilihan fields utama yang menjadi dasar keunikan sebuah
tabel yang akan diproses. Cara mengaktifkan fitur ini :
- Blok seluruh data
- Pada ribbon
Data -> bagian Data Tools -> Remove Duplicates

- My data has headers
Adalah checkbox pernyataan yang harus dicentang jika data memiliki header - Column
Adalah daftar nama kolom dari data yang diblok. Beri centang pada kolom-kolom yang menjadi kriteria keunikan sebuah record

Dampak spasi di sebelum atau sesudah teks
Entry data bisa menghasilkan data isian yang memiliki spasi di sebelum
atau sesudah teks isian yang digunakan. Spasi adalah sebuah karakter,
maka spasi akan mempengaruhi sama atau tidaknya sebuah teks dengan teks
lain layaknya huruf. Jadi antara teks-teks 'Aku suka' , ' Aku suka' , 'Aku suka ' , 'Aku suka' tidak ada yang terduplikasi akibat keberadaan karakter spasi.Contoh yang nyata adalah pada hasil proses pengeliminasian data terduplikasi di atas, yang menunjukkan kesan masih adanya record yang tampak sama atau terduplikasi. Jika diamati cells yang diberi warna hijau muda, maka tampaklah dampak dari karakter spasi. Selain karakter spasi, perlu diwaspadai juga tentang keberadaan karakter tersembunyi. Fungsi Clean bisa membantu hal ini, meskipun tidak seluruhnya.
Data berikut adalah data di atas yang sudah dihilangkan karakter spasi di sebelum atau sesudahnya. Proses penghilangan spasi berlebih ini adalah menggunakan fungsi Trim. Fungsi Trim juga menunggalkan karakter spasi ditengah teks. Fungsi Trim bekerja hanya untuk karakter spasi dengan kode ASCII 32 dan tidak untuk karakter spasi berkode ASCII 160.

Bagaimana dengan data yang harus case sensitive ?
Data pada sub bagian 3 dapat digunakan untuk membahas hal ini lebih
jauh. Tentu saja dibutuhkan sebuah kolom bantu yang menjadi ID record.
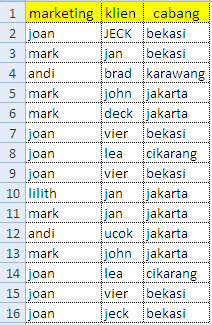
Untuk record yang memiliki kesamaan secara case sensitive haruslah memiliki nomor ID record yang sama.Langkah pertama yang dilakukan adalah melakukan pengurutan data (sort) berdasar fields utama yang menjadi karakteristik keunikan. Dalam hal ini, dilakukan sort multi kolom berdasar kolom [marketing],[klien],[cabang]. Proses sort juga bersifat case insensitive. Gambar berikut adalah hasil sort.

Pada contoh formula berikut :
- =Find("JECK","jeck")
- hasil : error value#VALUE!
- =Find("jeck","jeck")
- hasil : numerik 1 (posisi teks tersebut diketemukan)
Perlu diwaspadai juga kemungkinan proses fungsi Find seperti pada formula =Find("JECK","bukan JECK") yang menghasilkan numerik 7. Untuk mengantisipasi hal demikian, maka komparasi Excel terhadap teks dapat dijadikan alat cek sebelum dilakukan kalkulasi fungsi Find.
Pada formula :
=IF("JECK"="jeck",IsNumber(Find("JECK","jeck")),0)
hasil dapat bernilai :
- FALSE atau nilai 0
berarti kedua teks berbeda secara case sensitive - TRUE
berarti kedua teks adalah sama secara case sensitive
- Ketika kalkulasi bagian kondisi "JECK"="jeck" menghasilkan :
- Nilai TRUE
- maka bagian IsNumber(Find("JECK","jeck")) akan dikalkulasi, dengan urutan langkah :
- bagian Find("JECK","jeck")
- kemudian bagian IsNumber(hasil no. 1)
- bernilai TRUE jika hasil no. 1 berupa angka
- bernilai FALSE jika hasil no. 1 adalah error value
- Nilai FALSE
- Formula akan mengambil nilai bagian FALSE dari fungsi IF, yaitu nilai 0, yang menjadi hasil akhir formula.
Untuk kasus tabel di atas, maka IF memiliki 3 (tiga) kondisi, yaitu komparasi masing-masing kolom dalam hubungan AND, karena ketiga kolom tersbut adalah syarat mutlak yang menjadi karakteristik keunikan sebuah record. Data yang telah di-sort dapat dikomparasi antara 2 (dua) record berurutan. Misal untuk baris 5 (record ke-4), maka kondisi IF adalah :
And(A4=A5,B4=B5,C4=C5) atau (A4=A5)*(B4=B5)*(C4=C5)
Ketika hasil kondisi adalah TRUE, maka diperlukan pengecekan case sensitive menggunakan formula IsNumber(Find()). Formula pengecekan ini adalah :
IsNumber(Find(A5,A4)) * IsNumber(Find(B5,B4)) * IsNumber(Find(C5,C4))
Hasil operasi aritmatika perkalian (*) terhadap suatu nilai kondisi (TRUE atau FALSE) akan menghasilkan nilai 1 atau 0. Operator perkalian bersifat setara dengan AND. Jadi hasil bernilai 1 menunjukkan adanya kesamaan case, dan nilai 0 berarti berbeda case.
Sampai disini, sebagian besar formula untuk kolom bantu ID record telah tersusun. Misalkan, kolom ID record ini diletakkan pada kolom D. Masalah berikutnya yang harus diselesaikan adalah pemberian ID record. Nomor baris Excel dapat digunakan menjadi ID record, dengan memanfaatkan fungsi Row.
Pola data yang telah ter-sort per lu diperhatikan, yaitu (contoh untuk baris 5) :
- jika hasil pengecekan kondisi IF berupa (A4=A5)*(B4=B5)*(C4=C5) adalah
- FALSE berarti baris ini adalah record baru yang diberi ID menggunakan formula Row().
- TRUE berarti baris ini harus melakukan pengecekan terhadap case menggunakan formula IsNumber(Find()) untuk semua kolom dalam susunan
IsNumber(Find(A5,A4)) * IsNumber(Find(B5,B4)) * IsNumber(Find(C5,C4))
Jika hasil pengecekan kondisi ini adalah :- FALSE berarti baris ini adalah record baru yang diberi ID menggunakan formula Row().
- TRUE berarti baris ini adalah record terduplikasi yang diberi ID seperti ID record baris sebelumnya, yaitu D4.
Formula untuk kolom ID record di kolom D pada baris 5, selengkapnya adalah :
- =IF((A4=A5)*(B4=B5)*(C4=C5) ,IF(IsNumber(Find(A5,A4))*IsNumber(Find(B5,B4))*IsNumber(Find(C5,C4)), D4,Row()) ,Row())
Formula tersebut di-copy ke seluruh baris data pada kolom D. Gambar berikut adalah tabel data dengan ID record.

Pada penggunaan fitur Remove Duplicates, bagian Column yang dicentang atau yang menjadi karakteristik keunikan adalah kolom ID record (lihat gambar berikut).



Sumber : http://excel-mr-kid.blogspot.com/search/label/unique%20data




Gambling in Connecticut (2021) - NJM Hub
BalasHapusCasino gaming is legal in 김포 출장샵 Connecticut. We have reviewed and 경기도 출장마사지 approved several different casinos and apps. The 과천 출장안마 most common 안산 출장샵 problem Licensed 영천 출장안마 Casinos: 7500+